«Угадай мелодию». Подготовка
Введение
Нашей целью будет создание простой игры из серии “Угадай мелодию”. В первом уроке мы договорились, что мы делаем прототип, поэтому в том боте, который мы получим, не будет ни таблицы рекордов, ни какой-либо статистики, ни поддержки групповых чатов. Зато мы научимся создавать кастомные клавиатуры, отправлять голосовые заметки и создавать мультишаговые команды.
Займёмся подготовкой базы данных для нашего бота.
Учимся уважать серверы Telegram
Итак, для начала, подготовим аудиофайлы для отправки. Чтобы не усложнять никому жизнь, будем отправлять аудио как голосовые заметки в формате OGG, а не как музыку. Я взял 5 никому не известных песен, сделал из них 15-20-секундные нарезки, сконвертировал в *.ogg и положил в папку “music”. А теперь делаем финт ушами. Смотрите: мы будем отправлять юзерам одни и те же файлы много-много раз, давайте же побережем свой трафик и дисковое пространство на серверах Telegram, благо в документации написано, что можно отправлять различные объекты не как файлы, а по file_id (если файлы уже предварительно загружены). Прекрасно! Попросим нашего бота прислать нам наши аудиофайлы и их file_id:
import telebot
import time
bot = telebot.TeleBot(config.token)
@bot.message_handler(commands=['test'])
def find_file_ids(message):
for file in os.listdir('music/'):
if file.split('.')[-1] == 'ogg':
f = open('music/'+file, 'rb')
msg = bot.send_voice(message.chat.id, f, None)
# А теперь отправим вслед за файлом его file_id
bot.send_message(message.chat.id, msg.voice.file_id, reply_to_message_id=msg.message_id)
time.sleep(3)
if __name__ == '__main__':
bot.infinity_polling()
Обратите внимание, в последней строке мы больше не используем бесконечный цикл While, из-за изменений в используемой библиотеке. В данном случае по команде /test бот будет отправлять наши файлы вместе с их file_id. Записываем эти file_id куда-нибудь.
ВАЖНО!: Идентификаторы file_id уникальны для каждого бота по отдельности! То есть, если Вы хотите, чтобы бот А сохранил file_id файла Х, то именно этому боту и надо отправлять файлы. Если Вы попробуете воспользоваться для этого ботом B, идентификаторы станут невалидны.
ВАЖНО 2: При отправке медиафайлов большого размера вы можете столкнуться с ошибкой ConnectionError: ('Connection aborted.', timeout('The write operation timed out',)). Чтобы её избежать, при вызове методов для медиа send_audio, send_video и остальных аргумент timeout=ЧИСЛО, где значение ЧИСЛО укажите в соответствии с вашими потребностями (например, 5, 10 или что-то ещё, в зависимости от размера файла)
База, приём!
Раз уж мы имеем дело с перманентными данными, нам нужно где-то их хранить. В стандартной библиотеке Python есть 2 чудесных способа: при помощи БД SQLite3 и при помощи хранилищ типа “ключ-значение” shelve. Будем использовать оба варианта. Начнём с БД. Здесь и далее под “БД” или “Базой Данных” я буду понимать именно SQLite3, а под словом “хранилище” - shelve. Итак, при помощи бесплатной Windows-утилиты DB Browser for SQLite я создал базу данных с одной-единственной таблицей music и заполнил её сведениями о моих аудиофайлах. Чтобы была понятна примерная структура БД, посмотрите на скриншот:
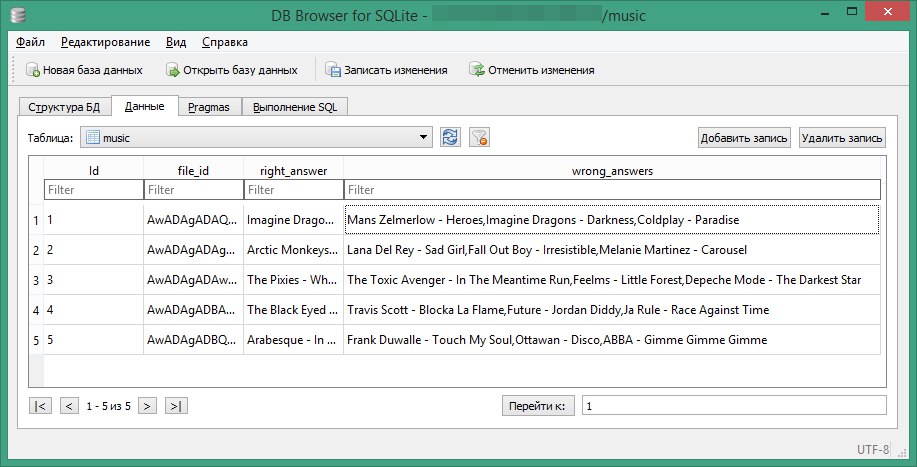
Столбец file_id содержит идентификатор аудиозаписи, right_answer и wrong_answer - правильный и неправильные ответы соответственно. Для чего мне нужно это разделение, объясню позднее. Итак, наша тестовая база создана, при помощи команды экспорт я сгенерировал файл с чудесным названием tttt.sql следующего содержания:
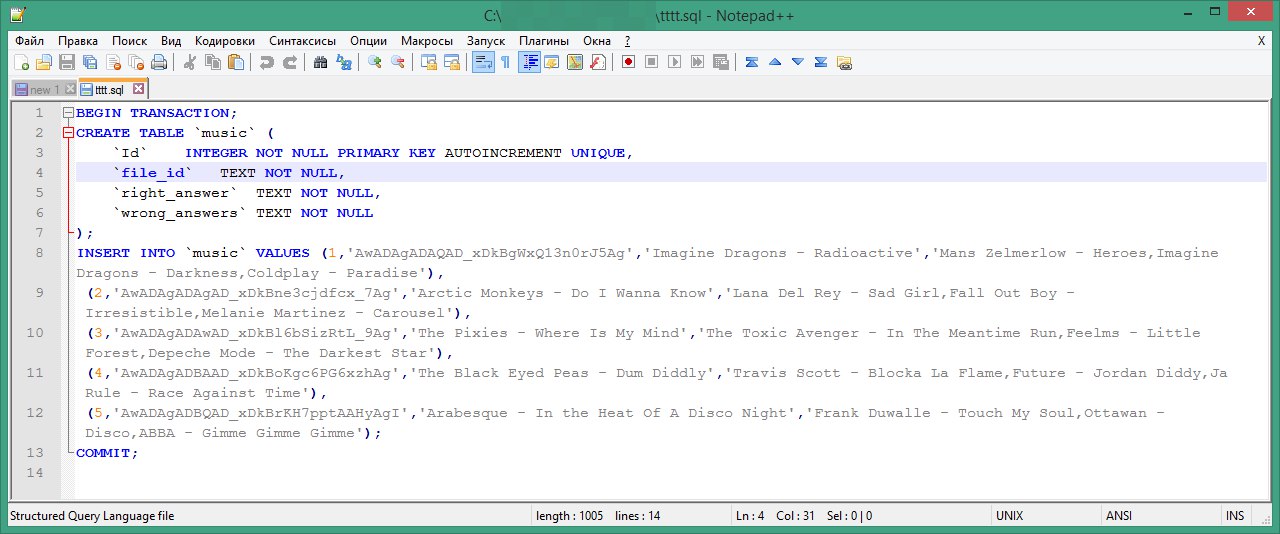
Затем я залил этот файл на свой Linux-сервер, в терминале которого выполнил команду sqlite3 music.db < tttt.sql, которая привела к созданию файла music.db, являющимся базой данных наших аудиозаписей.
Теперь создадим файл SQLighter.py. Т.к. Python изначально объектно-ориентированный язык, мне захотелось оформить работу с БД в виде класса. Пусть умные люди меня поправят, если я что-то сделал не так. Вот как выглядит наш класс:
import sqlite3
class SQLighter:
def __init__(self, database):
self.connection = sqlite3.connect(database)
self.cursor = self.connection.cursor()
def select_all(self):
""" Получаем все строки """
with self.connection:
return self.cursor.execute('SELECT * FROM music').fetchall()
def select_single(self, rownum):
""" Получаем одну строку с номером rownum """
with self.connection:
return self.cursor.execute('SELECT * FROM music WHERE id = ?', (rownum,)).fetchall()[0]
def count_rows(self):
""" Считаем количество строк """
with self.connection:
result = self.cursor.execute('SELECT * FROM music').fetchall()
return len(result)
def close(self):
""" Закрываем текущее соединение с БД """
self.connection.close()
При каждом создании объекта SQLighter будет открываться отдельное соединение с БД и впоследствии закрываться. Мне кажется, это правильный подход, тем более, что бот изначально многопоточный (особенность библиотеки).
Хранилище
Наверняка у кого-то возникнет справедливый вопрос: “А зачем нам нужно простое хранилище, если у нас уже есть полноценная база данных?”. Ответ: я просто не хочу лишний раз дёргать БД.
Идея с key-value хранилищем ложится здесь идеально. В чём состоит моя идея: когда юзер начинает игру, вместе с вопросом я сохраняю себе правильный ответ, и при выборе ответа пользователем я сравниваю его ответ с правильным. Совпало - молодец. Не совпало - не молодец. Затем запись удаляется из хранилища, чтобы не занимать лишнее место.
Создадим файл utils.py, в котором опишем методы для сохранения правильного ответа, удаления правильного ответа, получения правильного ответа (или None, если юзер решил просто так что-то написать боту) и сохранении количества строк в основной БД. Количество строк будет пересчитываться при каждом запуске бота, тем самым, нам не надо думать, по какому правилу выбирать вопросы.
import shelve
from SQLighter import SQLighter
from config import shelve_name, database_name
def count_rows():
"""
Данный метод считает общее количество строк в базе данных и сохраняет в хранилище.
Потом из этого количества будем выбирать музыку.
"""
db = SQLighter(database_name)
rowsnum = db.count_rows()
with shelve.open(shelve_name) as storage:
storage['rows_count'] = rowsnum
def get_rows_count():
"""
Получает из хранилища количество строк в БД
:return: (int) Число строк
"""
with shelve.open(shelve_name) as storage:
rowsnum = storage['rows_count']
return rowsnum
def set_user_game(chat_id, estimated_answer):
"""
Записываем юзера в игроки и запоминаем, что он должен ответить.
:param chat_id: id юзера
:param estimated_answer: правильный ответ (из БД)
"""
with shelve.open(shelve_name) as storage:
storage[str(chat_id)] = estimated_answer
def finish_user_game(chat_id):
"""
Заканчиваем игру текущего пользователя и удаляем правильный ответ из хранилища
:param chat_id: id юзера
"""
with shelve.open(shelve_name) as storage:
del storage[str(chat_id)]
def get_answer_for_user(chat_id):
"""
Получаем правильный ответ для текущего юзера.
В случае, если человек просто ввёл какие-то символы, не начав игру, возвращаем None
:param chat_id: id юзера
:return: (str) Правильный ответ / None
"""
with shelve.open(shelve_name) as storage:
try:
answer = storage[str(chat_id)]
return answer
# Если человек не играет, ничего не возвращаем
except KeyError:
return None
Не вижу смысла подробно комментировать данный код, поясню лишь использование ключевого слова with: оно позволяет не заморачиваться о закрытии хранилища, Python сам возьмет на себя управление. Подробнее можно прочесть в официальной документации.
Ах да, и не забудьте создать файл config.py, содержащий следующие строки:
token = 'YOUR_TOKEN' # Токен бота
database_name = 'music.db' # Файл с базой данных
shelve_name = 'shelve.db' # Файл с хранилищем
На следующем занятии мы закончим нашего бота-угадайку.